The goldilocks metric: why your AI needs to stop crying wolf
What if a smoke detector with 99.9% accuracy could burn your house down? Welcome to the paradox of precision and recall—where being too good makes you terrible.

The goldilocks metric: why your AI needs to stop crying wolf
What if I told you that a smoke detector with 99.9% accuracy could burn your house down? Or that a security system catching every single intruder might destroy your business? Welcome to the paradox of precision and recall—where being too good at one thing makes you terrible at everything else.
This is the story of F1-Score, the metric that forces your AI to grow up and stop making excuses.
The boy who cried wolf meets artificial intelligence
Remember that old fable about the boy who cried wolf? Turns out, he'd make a terrible machine learning model. Too many false alarms (low precision), and nobody believes you anymore. But here's the twist—what about the boy who never cried wolf? He'd have perfect precision (never wrong when he shouts), but terrible recall (missed every actual wolf).
In the industrial world, these aren't just bedtime stories. They're million-dollar mistakes happening every day.
Consider smoke detectors, which are "designed to commit many Type I errors (to alert in many situations when there is no danger), because the cost of a Type II error (failing to sound an alarm during a major fire) is prohibitively high." They prioritize recall—catching every fire—even if it means 3 AM false alarms from burnt toast.
Meet precision and recall: the odd couple of AI
Before we dive into F1-Score, let's meet its parents:

Fig. 1: The precision-recall trade-off visualized: High precision misses failures (costly emergencies), while high recall creates false alarms (wasted inspections). The real cost isn't in the percentages—it's in the dollars lost.
Precision: The perfectionist "When I say there's a problem, there's definitely a problem."
In your water pump facility monitoring 1,000 pumps:
- AI alerts: "These 10 pumps will fail!"
- Reality: 8 actually fail
- Precision = 80% (pretty good at not crying wolf)
Recall: The paranoid guardian "I'll catch every problem, even if I have to check everything twice."
Same facility:
- Total failures this month: 15 pumps
- AI caught: 12 of them
- Recall = 80% (good at finding actual problems)
But here's where it gets interesting...

Fig. 2: Meet the odd couple of AI: Precision only speaks when certain (but misses clues), while Recall suspects everyone (including innocent bystanders). Neither works well alone.
The industrial dilemma: when both heroes become villains
Imagine you're running a manufacturing plant. I'll give you two AI systems to choose from:
System A: The alarm-happy intern
- Flags 200 potential motor failures per month
- Catches 95% of actual failures (recall = 0.95)
- But 150 are false alarms (precision = 0.25)
- Your maintenance team now ignores most alerts
System B: The overcautious expert
- Flags only 5 potential failures per month
- When it flags, it's right 95% of the time (precision = 0.95)
- But misses 75% of actual failures (recall = 0.25)
- Your motors fail without warning
Which would you choose? Trick question—they're both disasters.
Enter F1-Score: the peacemaker
F1-Score is like a marriage counselor for precision and recall. It uses the harmonic mean (fancy math that heavily punishes extremes) to find balance:
F1 = 2 × (Precision × Recall) / (Precision + Recall)
Why harmonic mean instead of simple average? Because it's harsh on imbalance:
- Precision = 0.95, Recall = 0.05 → Average = 0.50, F1 = 0.095 (Ouch!)
- Precision = 0.50, Recall = 0.50 → Average = 0.50, F1 = 0.50 (Balanced)
The harmonic mean exposes the truth: a model that's brilliant at one thing but terrible at another is still terrible.
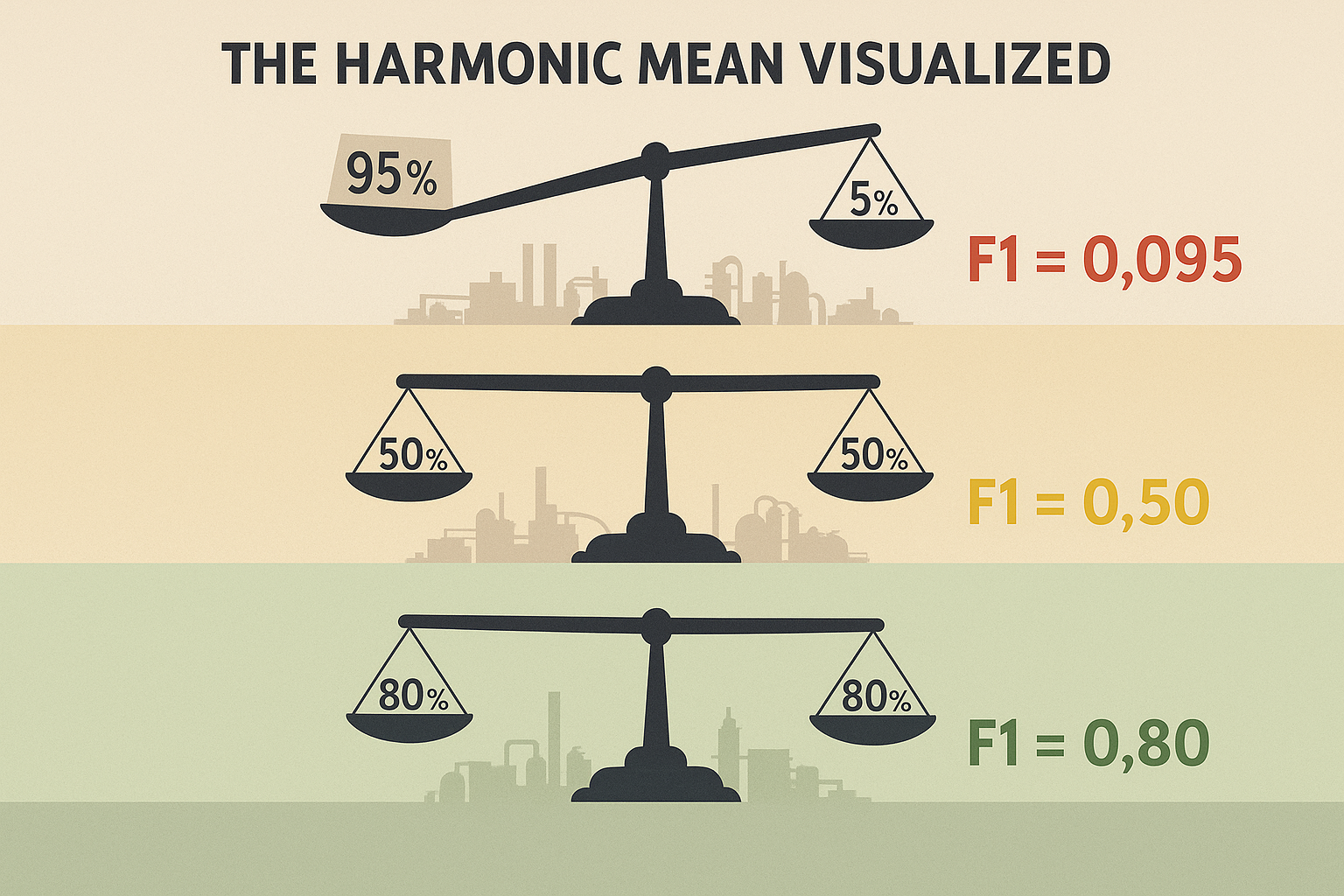
Fig. 3: The harmonic mean is harsh but fair: extreme imbalance between precision and recall yields terrible F1-Scores, forcing models to find equilibrium. A brilliant specialist that fails at everything else scores worse than a balanced generalist.
Real money, real problems
Let me show you why this matters with actual dollars:
Scenario: Predictive maintenance for water pumps
You manage 1,000 pumps. Typically, 10 fail per month.
The high-precision disaster:
- 8 alerts, 7 correct
- Precision: 87.5% (looking good!)
- Recall: 70% (missed 3 failures)
- Cost: 3 × $15,000 emergency repairs = $45,000
The high-recall money pit:
- 20 alerts, catches all 10 failures
- Recall: 100% (perfect!)
- Precision: 50% (10 false alarms)
- Cost: 10 × $1,000 unnecessary inspections = $10,000
The F1-optimized sweet spot:
- 12 alerts, 9 correct, 1 missed
- F1-Score: 0.82
- Cost: $3,000 false alarms + $15,000 missed = $18,000
- Saves $27,000 vs high-precision approach!
When F1-Score shines (and when it doesn't)
A pregnancy test manufacturer needs extremely high precision because "people might react to a positive test by suddenly getting married or buying a house." False positives have huge consequences. But fire alarms need high recall because "what is more important is making sure that when there is a fire it is detected 100% of the time. We can accept the odd false alarm."
F1-Score is perfect when:
- False positives and false negatives cost roughly the same
- You need balanced performance
- You're comparing models
F1-Score fails when:
- Costs are wildly imbalanced (nuclear plant safety vs. email spam)
- You have extreme class imbalance (finding 1 defect in 10,000 products)
- Business requirements demand optimizing one metric
The ML acronym party: where F1 fits in
In the grand ecosystem of machine learning metrics, F1-Score bridges two worlds:
Regression metrics (for continuous values):
- MAE, RMSE, MAPE: "How far off were we?"
- R²: "How much variance did we explain?"
Classification metrics (for categories):
- Accuracy: "What percentage were correct?" (dangerous with imbalanced data)
- Precision/Recall: "The parent metrics"
- F1-Score: "The balanced child"
- AUC-ROC: "Performance across all thresholds"
- Confusion Matrix: "The detailed breakdown"
Modern deep learning models—whether CNNs for image recognition, RNNs for time series, or transformers like BERT for text—all need these metrics. But F1-Score is especially critical for imbalanced problems: fraud detection, disease diagnosis, defect identification.

Fig. 4 The metric paradox: Perfect scores on yesterday's problems don't guarantee success with tomorrow's surprises. F1-Score is a compass pointing toward balance, not a guarantee of safety.
Beyond vanilla F1: the variant menu
Standard F1 treats precision and recall equally. But what if they're not equal?
F2-Score: Weights recall twice as heavily
- Use when missing problems is twice as bad as false alarms
- Common in medical screening
F0.5-Score: Weights precision twice as heavily
- Use when false alarms are twice as costly as missed detections
- Common in legal/financial applications
The formula: Fβ = (1 + β²) × (Precision × Recall) / (β² × Precision + Recall)
The bottom line: finding your goldilocks zone
"Machine learning models are a means to an end, not the end goal itself." The question isn't "what's my F1-Score?" but "what business problem am I solving?"
Here's your practical guide:
-
Calculate the costs
- False alarm: $X
- Missed detection: $Y
- If X ≈ Y, optimize F1
- If X >> Y, optimize precision
- If Y >> X, optimize recall
-
Set your thresholds
- F1 > 0.8: Production-ready for most applications
- F1 = 0.6-0.8: Usable but needs improvement
- F1 < 0.6: Back to the drawing board
-
Monitor in production
- Track precision, recall, and F1 separately
- Watch for drift over time
- Alert when any metric drops below threshold
The truth nobody tells you
Perfect F1-Score doesn't mean perfect model. I've seen models with F1 = 0.85 fail spectacularly because:
- They were trained on yesterday's problems
- The cost assumptions changed
- Edge cases weren't in the training data
F1-Score is a compass, not a destination. It points toward balance but can't tell you if you're climbing the right mountain.
The real skill isn't maximizing F1-Score—it's knowing when to ignore it. Because sometimes, the boy who cried wolf would have saved the village if he'd just cried a little louder, a little sooner, even if he was wrong most of the time.
Your AI doesn't need to be perfect. It needs to be useful. And F1-Score, despite its mathematical elegance, is just one way of defining useful in a world full of trade-offs, where the cost of being wrong is never quite what we calculated it to be.
Next time someone shows you a model with "great F1-Score," ask them: "Great for what?" Because in the end, the best metric is the one that keeps the lights on, the pumps running, and the wolves at bay—whether it cries too much or too little.
Related articles
Project Report: Symptomatic Alarm Pattern Discovery and Root Cause Analysis
A formal summary of Project ID a496e3ae-5149-4a15-86dd-a3aee47f493f. This report details the full execution of the project, from the analysis of 102,319 alarm records to the development of an analytical pipeline for anomaly detection and the strategic vision for future capabilities.

The Prognostics & RUL Cheat Sheet: A Guide for Real-World Assets
Ready to move from theory to reality with predictive maintenance? The first step is choosing the right RUL model—a choice that depends entirely on your data. This comprehensive cheat sheet demystifies the options, detailing four key methodologies.
Ready to get started with ML4Industry?
Discover how our machine learning solutions can help your business decode complex machine data and improve operational efficiency.
Get in touch