The Ultimate Machine Learning Cheat Sheet for Non-Specialists
Demystifying machine learning concepts in plain English - a comprehensive guide that breaks down complex ML terminology and models into practical insights anyone can understand.

The ultimate machine learning cheat sheet for non-specialists
Ever wondered why everyone keeps talking about machine learning but nobody seems able to explain it clearly? Have you nodded along in meetings while secretly wondering what the difference between a neural network and logistic regression actually is? You're not alone.
Here's something provocative: Most experts overcomplicate machine learning to make themselves sound smarter. The truth? The core concepts aren't that difficult to grasp if explained properly.
I've spent years translating technical jargon into plain English, and today I'm sharing the ultimate machine learning cheat sheet designed specifically for non-specialists. No PhD required—just practical knowledge you can actually use.
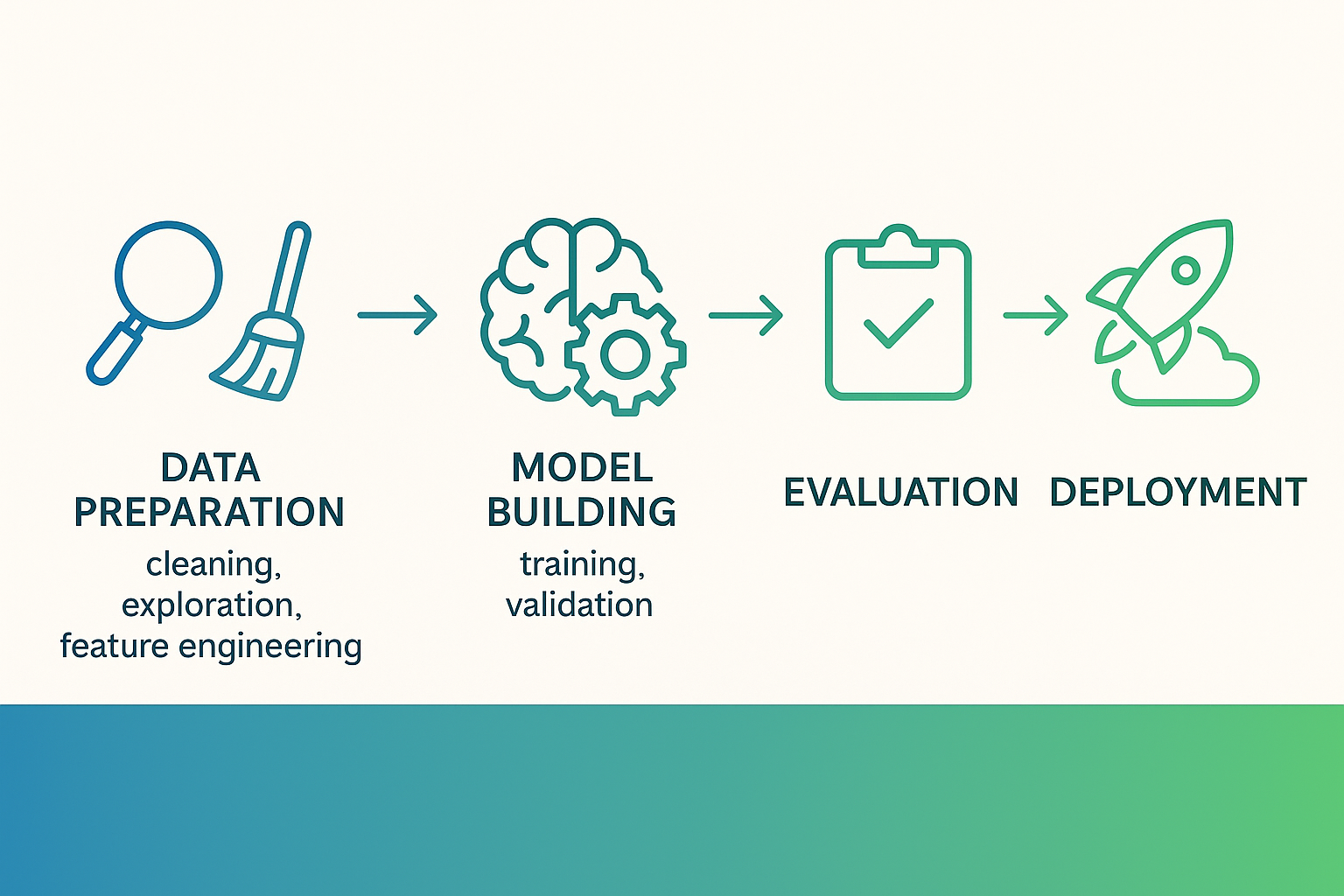
Fig. 1: Infographic capturing the full machine-learning workflow. Data Preparation (cleaning, exploration, feature engineering) → Model Building (training, validation) → Evaluation → Deployment
The machine learning journey: What are we trying to solve?
Machine learning, at its heart, is about teaching computers to learn patterns from data and make predictions or decisions without being explicitly programmed for each specific task. But how does that work in practice?
Let's break down the entire process into digestible parts that anyone can understand:
Part 1: Preparing your data (the foundation of everything)
Data validation & cleaning
What is it? Checking data for errors, inconsistencies, missing values, and outliers, then correcting or removing problematic data.
Why it matters: Ever heard "garbage in, garbage out"? No matter how sophisticated your model, bad data leads to bad results—period.
Think of data cleaning like preparing ingredients before cooking. Would you make a soup with unwashed vegetables or meat past its expiration date? Of course not. Similarly, you need to ensure your data is "fresh" and properly prepared before feeding it to your models.
The process can be time-consuming and tedious, but it's absolutely essential for reliable results. One challenging aspect is deciding how to handle missing data—do you remove those entries entirely or try to fill in the blanks with estimated values?

Fig. 2: A data scientist examining multiple visualizations of the same dataset
Exploratory data analysis (EDA)
What is it? Investigating your dataset to summarize its main characteristics, often with visual methods, looking for patterns, anomalies, and relationships.
Why it matters: Without understanding what's in your data, you're operating blind.
This is detective work—you're looking for clues. What's the average age in your customer dataset? Do sales spike on certain days? Is there a correlation between website visits and purchases? Good exploratory analysis reveals insights that guide your entire ML project.
Feature engineering & selection

Fig. 1: Feature-engineering “factory” in action
What is it? Creating new input variables from existing ones (engineering) and choosing the most relevant features for your model (selection).
Why it matters: The right features can significantly boost model accuracy, allow for simpler models, reduce overfitting risk, and cut down training time.
Think of features as the "ingredients" your model learns from. Good features make learning easier. Irrelevant features are like adding sawdust to cake batter—they provide no value and might even make things worse!
Part 2: Building and evaluating your model
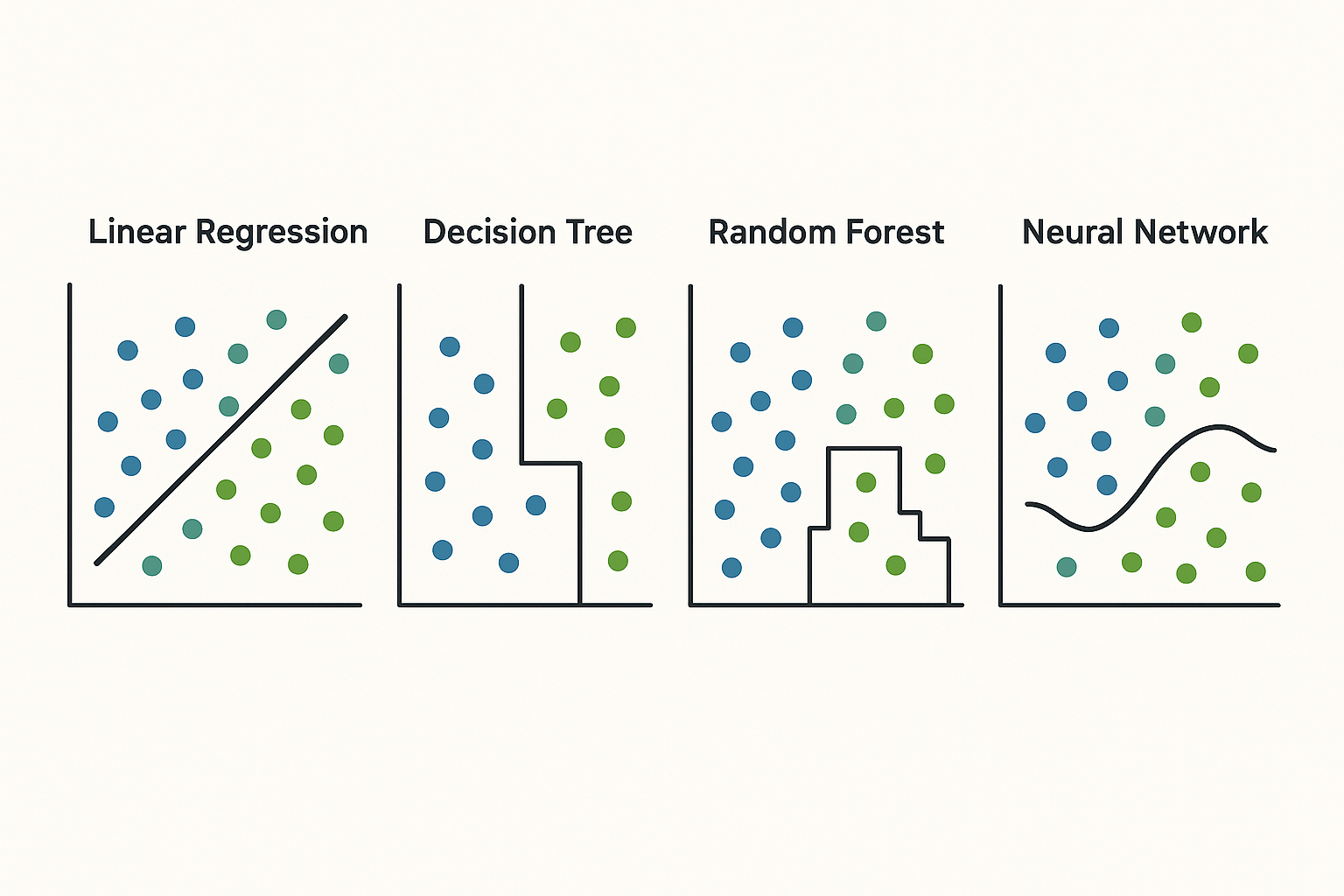
Fig. 1: Comparison of four machine learning models (Linear Regression, Decision Tree, Random Forest, Neural Network)
Splitting your data (the crucial separation)
What is it? Dividing your dataset into (usually) three parts:
- Training set: Used to "teach" the model
- Validation set: Used to tune model settings and make choices
- Test set: Used for final, unbiased evaluation of the chosen model
Why it matters: Without this separation, you'll have no idea if your model will work on new data.
Imagine teaching a student for an exam. The training set is study material. The validation set contains practice tests to see what study methods work best. The test set is the final exam that truly measures learning.
Choosing the right model type
This is fundamental! Ask yourself: "What am I trying to predict or discover?"
- Regression: Predicting a number (price, temperature, sales)
- Classification: Predicting a category (spam/not spam, fraud/legitimate)
- Clustering: Finding natural groupings without predefined labels
Using the wrong model type is like trying to hammer in a screw—you need the right tool for the job.
Part 3: Common machine learning models explained simply
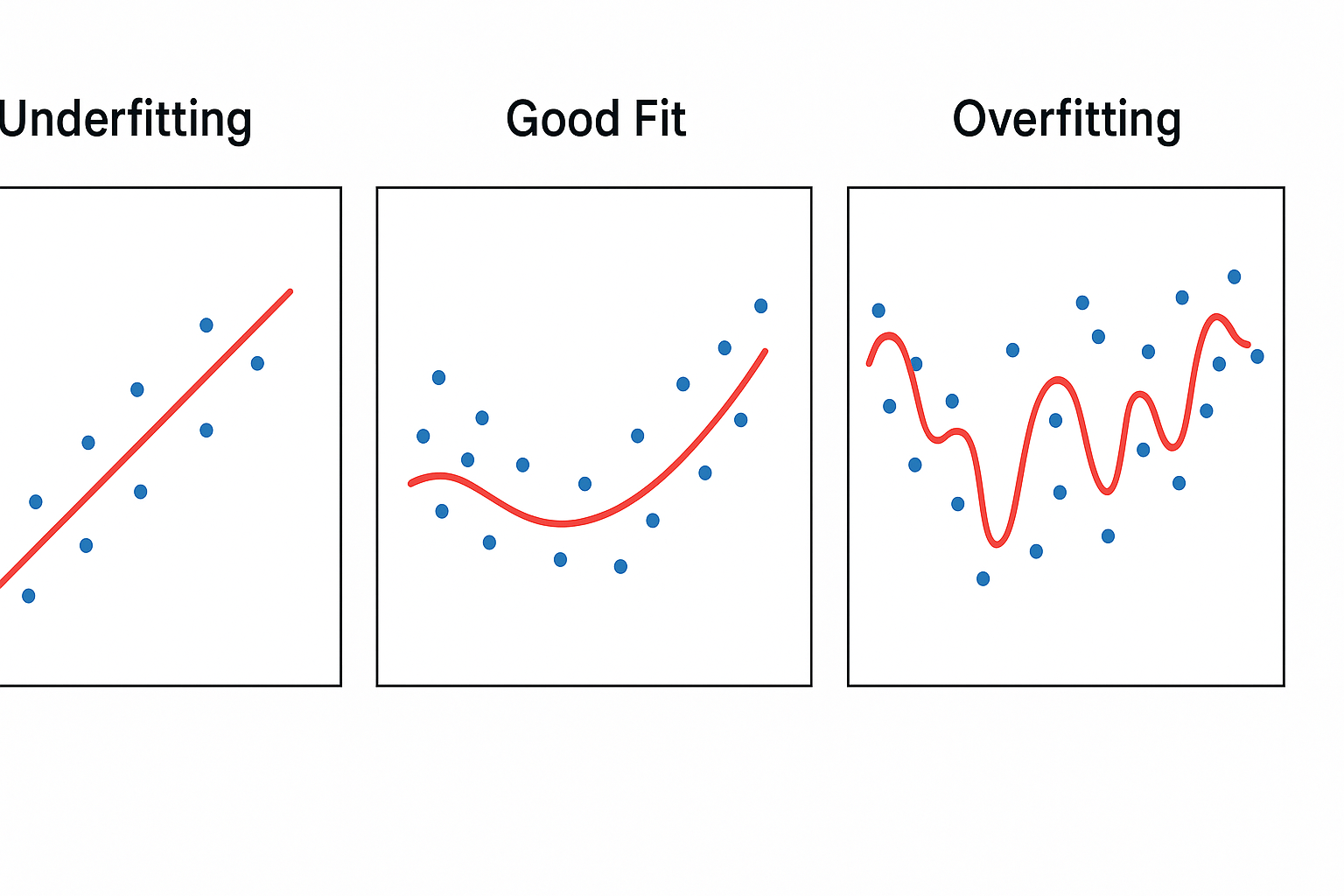
Fig. 1: Left shows underfitting (too simple, straight line missing the pattern), center shows good fit (balanced curve capturing the trend), right shows overfitting (overly complex curve hitting every point).
Linear regression: The classic starting point
What it is: Predicts a continuous value by fitting a straight line to data.
When to use it: When predicting quantities like sales, temperature, or prices.
Non-technical explanation: Imagine drawing the "best-fit" line through scattered dots on a graph. That line becomes your prediction model.
Advantages:
- Simple to understand and interpret
- Computationally inexpensive
- Great baseline model
Disadvantages:
- Assumes linear relationships (which are often not true for complex problems)
- Sensitive to outliers
Logistic regression (despite its name, it's for classification!)
What it is: Predicts the probability of a binary outcome (yes/no, spam/not spam).
When to use it: Binary classification problems like email spam detection or disease prediction.
Non-technical explanation: Instead of predicting a number, it predicts the likelihood (0-100%) that something belongs to a category.
Advantages:
- Outputs useful probabilities
- Simple to understand
- Computationally efficient
Decision trees: The intuitive flowchart
What it is: A tree-like model where each internal node represents a "test" on an attribute, each branch an outcome of the test, and each leaf node a class label or value.
When to use it: Classification and regression tasks where understanding the decision rules matters.
Non-technical explanation: Imagine a flowchart for making decisions. "Is the email from a known sender? Yes → Not Spam. No → Does it contain 'free money'? Yes → Spam."
Advantages:
- Easy to understand and visualize
- Handles both numerical and categorical data
- Makes few assumptions about data
Disadvantages:
- Prone to overfitting
- Can be unstable (small data changes can lead to very different trees)
Random forest: The wisdom of crowds
What it is: An ensemble method that builds multiple decision trees and outputs the average prediction (regression) or majority vote (classification).
When to use it: Complex classification and regression tasks where accuracy matters more than interpretability.
Non-technical explanation: Like asking many different "experts" (decision trees) for their opinion and going with the majority vote. Each tree sees a random subset of data, making them diverse.
Advantages:
- Higher accuracy than a single decision tree
- Robust to outliers and noise
- Less prone to overfitting
Disadvantages:
- Less interpretable than a single tree
- Can be slow to train on large datasets
Neural networks: The brain-inspired powerhouse
What it is: Models inspired by the human brain, with layers of interconnected "neurons" that process information.
When to use it: Complex problems like image recognition, natural language processing, and speech recognition.
Non-technical explanation: Think of a network of simple processing units. When many are layered deeply, they can learn incredibly intricate patterns—from identifying cat pictures to translating languages.
Advantages:
- Can achieve state-of-the-art performance on complex tasks
- Can learn features automatically from raw data
Disadvantages:
- Requires large amounts of data
- Computationally expensive to train
- Often a "black box" (hard to interpret decisions)
Part 4: From model to real-world value
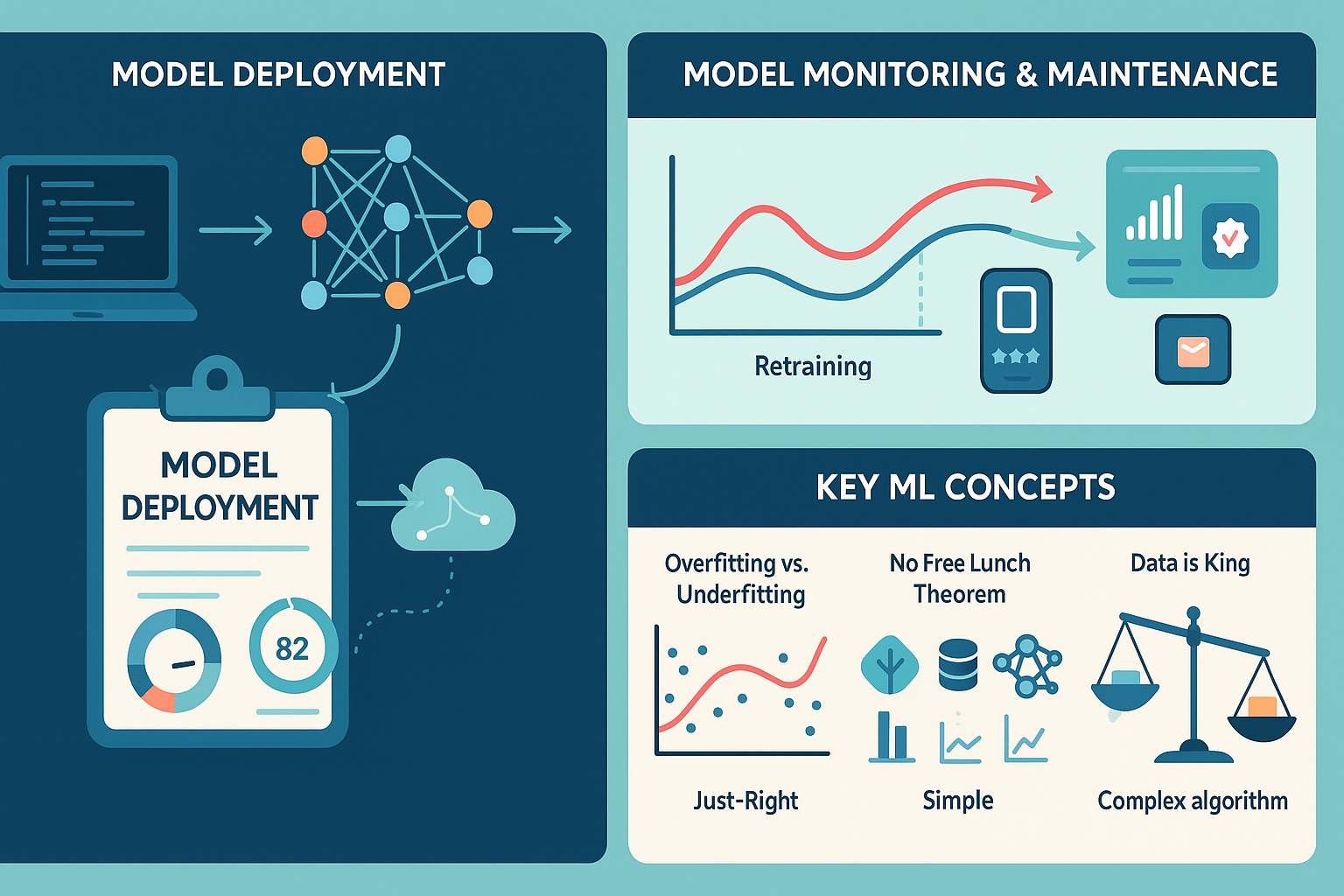
Fig. 1: Infographic covering deployment, monitoring, and key ML concepts.
Model deployment: Taking it live
What is it? Making your trained model available for use in a real-world application.
Why it matters: This is where your model starts generating actual value—predicting customer churn, recommending products, detecting fraud in real time.
Model monitoring & maintenance: The ongoing care
What is it? Continuously tracking performance and retraining as needed.
Why it matters: The world changes, and so does data! A model trained on last year's customer behavior might not be accurate today.
Key concepts every non-specialist should know
The overfitting/underfitting balance
- Overfitting: When your model learns the training data too well, including its noise. Like a student who memorizes answers but doesn't understand concepts.
- Underfitting: When your model is too simple and misses important patterns. Like a student who didn't study enough.
The "no free lunch" theorem
No single machine learning algorithm is universally best for all problems. You often need to try several—which is why understanding the strengths and weaknesses of each is so valuable.
Data is king
The quality and quantity of your data are typically more important than the specific algorithm chosen. Great algorithms can't compensate for poor data, but even simple algorithms can perform well with excellent data.
Where to go from here?
Machine learning isn't magic—it's a set of powerful tools that, when properly understood and applied, can provide remarkable insights and capabilities. The key is knowing which tool to use when, and how to prepare your data to get the best results.
What question could machine learning help you answer in your work or projects? What data do you already have that might contain hidden patterns waiting to be discovered?
The most exciting thing about machine learning isn't the algorithms—it's the problems they can help us solve.
What aspects of machine learning would you like me to explore more deeply in future posts? Let me know in the comments!
Related articles

From an Avalanche of Alerts to a Dialogue of Diagnosis: The C101 Compressor Story
We analyzed over 242,000 sensor records from a critical compressor, transforming a constant stream of noisy alerts into a clear, diagnostic language. This is the story of how we used machine learning to discover the hidden 'fingerprints' of inefficiency and failure, creating a data-driven roadmap to proactive maintenance and quantifiable business impact.

Your Data Is Talking. Here’s How to Listen.
We were handed a raw sensor dataset and a simple question: 'Can you do something with this?' In less time than a coffee break, we transformed that noisy data into a library of actionable 'Anomaly Fingerprints' that can predict failures before they happen. Here’s the step-by-step story.
Ready to get started with ML4Industry?
Discover how our machine learning solutions can help your business decode complex machine data and improve operational efficiency.
Get in touch